I’m looking at getting some help with my on-prem GitLab CE repository which is violently growing in size (upwards of 10GB per week). We are using GitLab CE in the following ways:
Version control of all source code (developer commits)
Source control for automation scripts (commit then pull later to execute in respective environments)
Commit tagging when source control is built (build server periodically checks for changes in a branch and kicks-off a build then tags the most recent commit associated with that successful build)
Unfortunately, this repository holds four years worth of stuff, including some historical binaries which aren’t used anymore (files between 50MB and 240MB). In each case of the binaries, they were only ever committed once but it looks like the binary was duplicated for each commit that was tagged.
The 240MB file has a single commit history from four years ago with an initial commit but somehow got replicated nearly 7000 times (compressed to 28MB). Using a GitExtensions plugin ‘Find large files’, I used it to delete every coopy of it in the repository via a ReWrite of history. After this process, instead of gaining back roughly 200GB of disk space, it took up 8GB more. I proceeded to use the same process for five other files between 50MB and 150MB and now my source control is 18GB larger than before I begin trying to get rid of the files.
I’ve since gone through and deleted old branches we don’t need anymore and deleted all tags for those branches. I’ve also completely deleted some old projects all-together. I’m not getting any free space back.
What can I do here guys? I’ve gone through and explicitly deleted unused binaries etc from the two most-recent branches. The disk usage has gone from 500GB to 640GB in the last couple of months.
Version: GitLab Community Edition 8.12.3
OS: Ubuntu
Filesystem: LVM mapped to /dev/mapper/gitlab-root (dm-0)
Project Sizes (according to GitLab in Admin Section of server website - Top 10): 750MB, 280MB, 240MB, 120MB,100MB,77MB,77MB,60MB, 53MB, 52MB
By repository you mean a single git repo is getting uncontrollably large or that your entire gitlab server is running out of space? Someone is checking crap in then, right? This sounds like a discussion you need to have internally with the people who commit stuff into this repo.
If I’m misunderstanding you, and it’s just that you’re running out of space on your server, I would also check these places:
cd /home/git
du -hs *
cd /var/opt/gitlab/git-data/repositories/
du -hs *
cd /var/opt/gitlab/gitlab-ci/builds
du -hs *
cd /var/log/gitlab
du -hs *
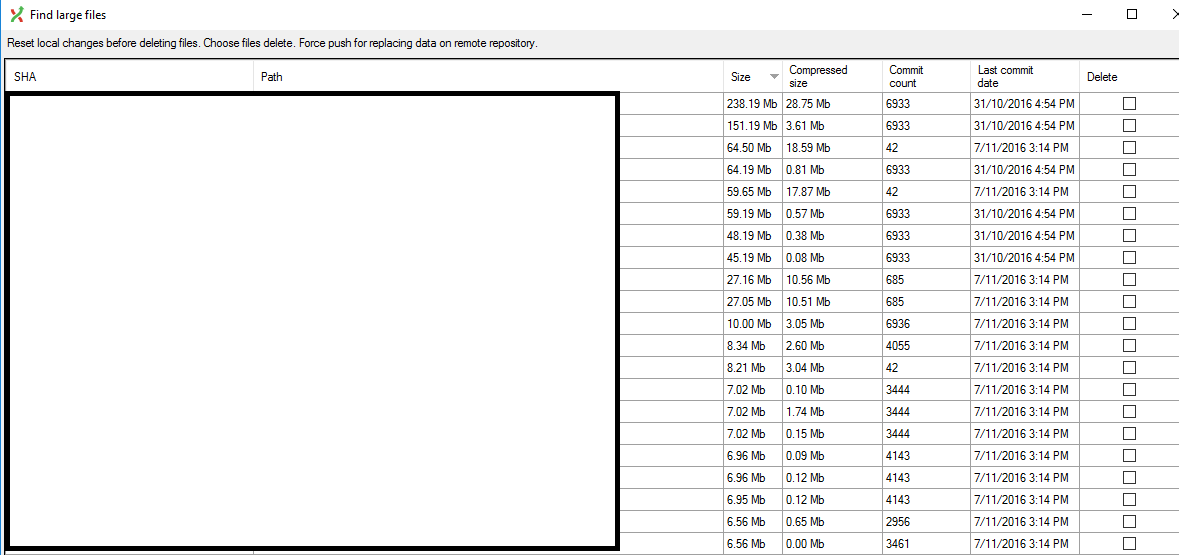
At the moment, I believe that the existing binaries in source control, and commit tagging combined, are causing the massive usage in space. See the below output from ‘Find large files’:
In particular, the files which have a commit count of 6933 were committed to source control once, four years ago. See the below commit history for one of these files:
Although we have removed these space wasters from the most recent branches, I’m not sure how to get rid of the other 6933 commits. We only have eight branches on this particular repository but each branch has many commit tags from builds.
So what is that gitlab-satellites thing? 23 gigs. I don’t have that folder. Also I wonder what is this “find large files” window you’re looking at. It looks like you found a random tool on the internet. What is it? What does it do?
It’s a deprecated feature. If you look at the top large file in the above screenshot, it has a compressed size of 28.75Mb and a commit count of 6933 contributing to 199GB of space usage on its own. I’ve deleted branches older than two years ago and every tag associated with those branches. The commit count for the file, or any other large file, didn’t go down.
Where are these files stored? in a database or the file system? I appreciate that GitLab will hang-on to data as long as something is referencing it. Outside of deleting a branch and all its tags, I don’t know what else is causing these commits to not be cleaned-up and why there are so many commits to begin with.
Looking at your commits, it seems someone did the usual bulk import of a giant folder of source code, but that the source code folder in svn was full of binaries, and that the person who committed the giant pile of binaries has continued to commit binaries in git. The problem here is the user who does this, or the developer who wrote a build script that checks crap into git. I have had good success when I explain to developers that this is not a good practice and that they need artifactory or a cache or package repository not git, for their binary storage. If you’re in a videogame development team and these are large artifacts, consider using git LFS.
Go back and study the import from whatever was done before and you’ll probably see that some “noob mistakes” were made. Git shouldn’t be used to “hold my 200 gigs of subversion repo crap in one git repo”, and certainly should not be used to hold a lot of binaries. That’s an anti-pattern that has to be stopped where it starts; With developers.
It almost sounds to me like what you’re trying to do is fix a bad import-from-svn-mess, when what might make more sense is to archive that repo and start over with a fresh git repo and have your team re-clone from a nice clean repo made by someone with more sense of what is really necessary. Those thousands of commits could be, for instance, someone using an svn-to-git tool and keeping 20 years of history on 10,000 files. In my opinion, moving from svn to git is a perfect time to squash all your svn history. Leave that history in svn. But it’s your call. Your team made the other call, and now you have 9000 revs? If so, ask the person who created the repo, why they did this?
Another possibility is that you are dealing with a team who loves to commit their .obj and .lib files into git, and who needs to be educated on how silly that is, and introduce them to the wonders of .gitignore, and gitlab-ci’s caching feature (to speed up CI builds on incrementally buildable projects).
Your fundamental question “why so many commits” needs to be redirected to the team who created those thousands of very large commits. Since you didn’t actually give a file name or a file extension, there’s very little anyone here can do to guess what you’re actually looking at.
Ok I was walking around and it hit me. Is that satellite feature bringing back your push-deletions because it’s basically replicating changesets from “satellites”?